MySQL 优化器导致暴涨案例分析
条评论案例描述
这里记录的是一次线上问题的分析过程,MySQL在执行形如select * from tb WHERE val IN (10, 20, 30) and id IN (1,2,3) and id IN (1,2,3,4,5)类型的SQL时,造成内存暴涨,引发OOM。这个SQL中IN的列表长度可能达到数十万个,而SQL总的长度不超过10M字节。注意到这个SQL中Where条件里有两个id IN(…),然后再把它们通过AND连接起来,意思是取两个列表的交集。通过线下测试可以发现,此SQL在MySQL 5.5上表现正常,很快就可以执行完成,而在5.6上执行时间非常长,而且内存不断上涨,直到引发OOM。于是就引出了几个问题: 1. 什么原因导致MySQL 5.6内存暴涨? 2. 为什么MySQL 5.5表现正常,而5.6有问题,是MySQL 5.6引入的BUG吗? 3. MySQL占用的内存量和SQL中的3个IN列表是什么关系? 4. 和数据量的大小或者数据分布有关吗?
案例分析
为了解释上面几个问题,首先需要在MySQL
5.6中复现问题,在MySQL实例上创建如下库和表,(这里只为阐述问题,表结构和线上不一样,但也能说明问题)
1
2
3
4
5
6
7
8
9root > create database db
root > use db
root > CREATE TABLE tb (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) NOT NULL DEFAULT '',
val int(11) NOT NULL DEFAULT ‘0’,
PRIMARY KEY (id),
KEY key_val (val)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Schema创建完成之后,不往里填充数据,就执行如下SQL,每个IN的列表长度都非常大,每个IN的列表都有10000个记录,SQL长度为143K字节。
1
SELECT 1 FROM tb WHERE (val IN(1,2,3,4,5….)) AND (id IN(1,2,3,4,5,6….)) AND (id IN(1,2,3,4,5,6….))
此SQL执行过程中,通过show
processlist查看,SQL的执行状态为statistics。说明执行过程正处于SQL优化阶段
 但是使用的内存量却不断上涨,内存使用量如下图:
但是使用的内存量却不断上涨,内存使用量如下图:
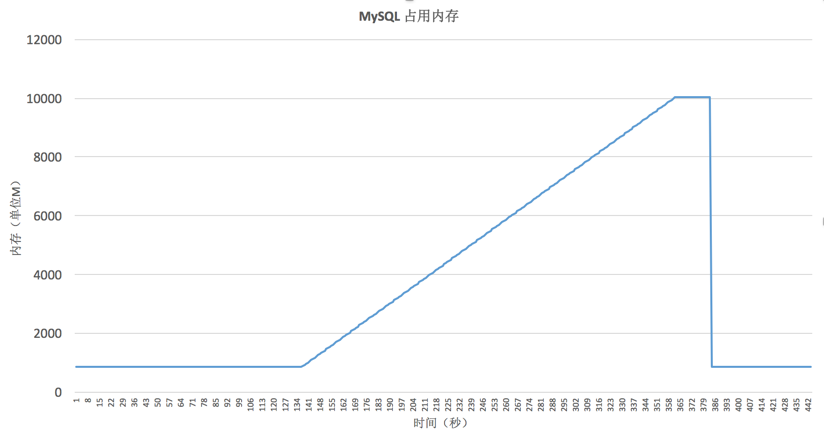
可以看到,内存使用量从864M,上涨到了10048M,SQL执行完成之后,内存使用量回落。在执行这条SQL期间,内存上涨了9G,大大超过了我们的预期。但是从另外一个层面来讲,由于新建的表结构只是空表,里面没有数据,说明内存占用只和SQL有关,和MySQL的数据分布无关。但是由于SQL长度非常大,不方便调试,我们不清楚SQL中的3个IN列表是如何影响内存使用的。因此我们需要生成各种不同类型的SQL,查看内存使用情况,然后找到一个典型的短SQL进行DEBUG。
生成SQL的脚本如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29#!/usr/bin/env python
#-*- coding:utf-8 -*-
import sys
def main():
if len(sys.argv) < 4:
print "Usage: python %s len1 len2 len3" % sys.argv[0]
return
SQL_FORMAT = "SELECT * FROM db.tb WHERE val in ({0}) AND id IN({1}) and id IN({2})"
in_len = []
for i in range(1, len(sys.argv)):
in_len.append(int(sys.argv[i]))
in_list = []
# Generate list for IN(....)
for i in range(3):
cur_list = []
for j in range(1, in_len[i]+1):
if i == 0:
cur_list.append(str(j))
else:
cur_list.append(str(j + in_len[0]*10))
in_list.append(','.join(cur_list))
print SQL_FORMAT.format(*tuple(in_list))
if __name__ == '__main__':
main()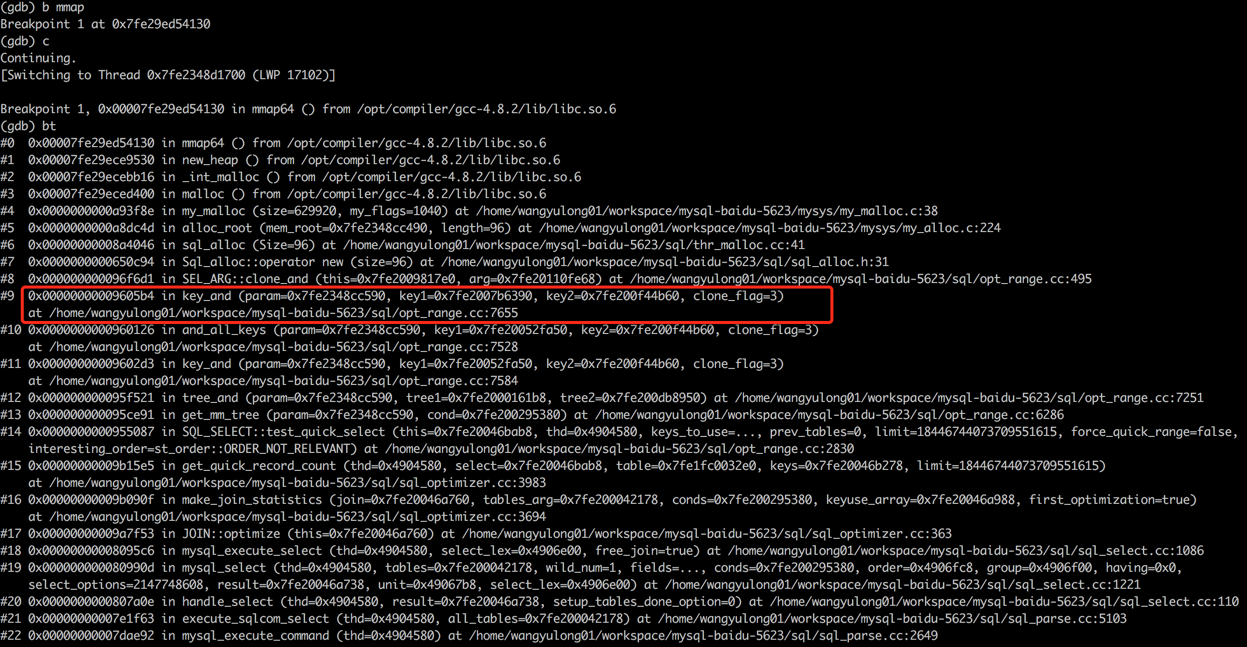 跟踪发现,每次申请内存都在key_and()中,然后调用SEL_ARG::clone_and()函数申请内存。
下面就要把源码文件sql/opt_range.cc打开看看,看看key_and()是怎么回事儿,为什么总是在分配内存
跟踪发现,每次申请内存都在key_and()中,然后调用SEL_ARG::clone_and()函数申请内存。
下面就要把源码文件sql/opt_range.cc打开看看,看看key_and()是怎么回事儿,为什么总是在分配内存
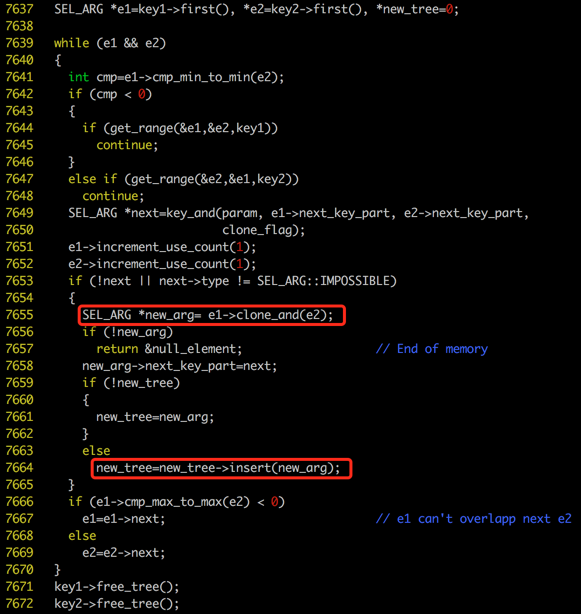 从上面代码中可以看到,在key_and()中,会把key1和key2两棵树merge到一起,形成新的一棵树,在merge两棵树的节点时分配内存。当新的树创建完成以后,再把key1和key2对应的树释放内存。源码看到这里,读者又要产生新的疑问了,key1和key2是什么?为什么要把它们merge到一起?回答这个问题,需要一点儿MySQL优化器的背景知识。
从上面代码中可以看到,在key_and()中,会把key1和key2两棵树merge到一起,形成新的一棵树,在merge两棵树的节点时分配内存。当新的树创建完成以后,再把key1和key2对应的树释放内存。源码看到这里,读者又要产生新的疑问了,key1和key2是什么?为什么要把它们merge到一起?回答这个问题,需要一点儿MySQL优化器的背景知识。
我们用Explain执行下SQL,看看用到的索引
 我们看到此SQL可能使用2个索引,一个是PRIMARY,另一个是我们创建的索引key_val。其中PRIMARY是主键索引,在InnoDB里也就是聚集索引;而key_val是针对val的索引,也就是二级索引,因为在InnoDB里二级索引保存的就是主键,所以只在索引key_val中,就可以同时获取到val的值和主键id的值。在SQL优化阶段刚开始的时候,MySQL优化器并不知道哪个索引更优,所以Explain的时候列出了2个possible_keys,MySQL需要进行比较,才能知道用哪个索引。MySQL优化器做比较的时候,会针对每个prossible_key创建一组红黑树,在这里因为有2个possible_key,所以优化器总要创建2组红黑树,红黑树的节点顺序根据key来作比较关键字。这个案例中,主键只有一个id,优化器针对主键索引只需要创建一棵红黑树就可以了。而二级索引key_val同时包含了val和id的信息,优化器针对key_val索引要创建2棵红黑树。经过多次DEBUG,将内存占用过多的问题定位到了在key_val红黑树的构建上,下文的讨论主要是针对索引key_val进行的。为了定为问题,我们需要知道优化器使用的数据结构,以及占用内存情况。
我们看到此SQL可能使用2个索引,一个是PRIMARY,另一个是我们创建的索引key_val。其中PRIMARY是主键索引,在InnoDB里也就是聚集索引;而key_val是针对val的索引,也就是二级索引,因为在InnoDB里二级索引保存的就是主键,所以只在索引key_val中,就可以同时获取到val的值和主键id的值。在SQL优化阶段刚开始的时候,MySQL优化器并不知道哪个索引更优,所以Explain的时候列出了2个possible_keys,MySQL需要进行比较,才能知道用哪个索引。MySQL优化器做比较的时候,会针对每个prossible_key创建一组红黑树,在这里因为有2个possible_key,所以优化器总要创建2组红黑树,红黑树的节点顺序根据key来作比较关键字。这个案例中,主键只有一个id,优化器针对主键索引只需要创建一棵红黑树就可以了。而二级索引key_val同时包含了val和id的信息,优化器针对key_val索引要创建2棵红黑树。经过多次DEBUG,将内存占用过多的问题定位到了在key_val红黑树的构建上,下文的讨论主要是针对索引key_val进行的。为了定为问题,我们需要知道优化器使用的数据结构,以及占用内存情况。
数据结构
为了简单起见,我们首先看看对于SELECT * FROM tb WHERE val IN(1,2,3,4,5,6,7)的情况。优化器使用的数据结构为SEL_ARG,并将它们组织成红黑树,其中SEL_ARG的主要成员定义如下:
1 | // 所在文件:sql/opt_range.cc |
构造红黑树的相关代码如下:
 在SELECT * FROM tb
WHERE val
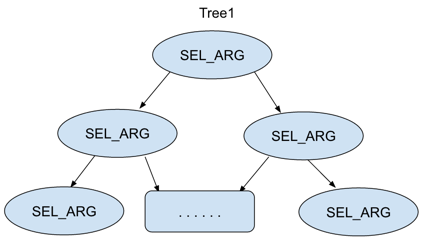
IN(1,2,3,4,5,6,7)中的IN参数列表,其实就是func->arguments(),优化器遍历这个列表,通过调用tree_or()构造一棵红黑树,最终的结果如下图所示,SEL_ARG不仅包含了字段的数值,而且还包含了字段的数据类型,还有一个指针next_key_part指向下一个索引子段的红黑树(可能为空指针)
在SELECT * FROM tb
WHERE val
IN(1,2,3,4,5,6,7)中的IN参数列表,其实就是func->arguments(),优化器遍历这个列表,通过调用tree_or()构造一棵红黑树,最终的结果如下图所示,SEL_ARG不仅包含了字段的数值,而且还包含了字段的数据类型,还有一个指针next_key_part指向下一个索引子段的红黑树(可能为空指针)
 为了说明问题,我们还需要构造一条稍微复杂一点儿的SQL:SELECT * FROM tb
WHERE val IN(1,2,3,4,5,6,7) AND id
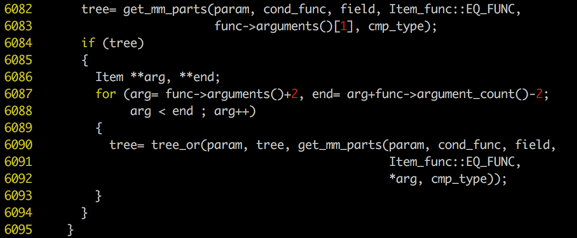
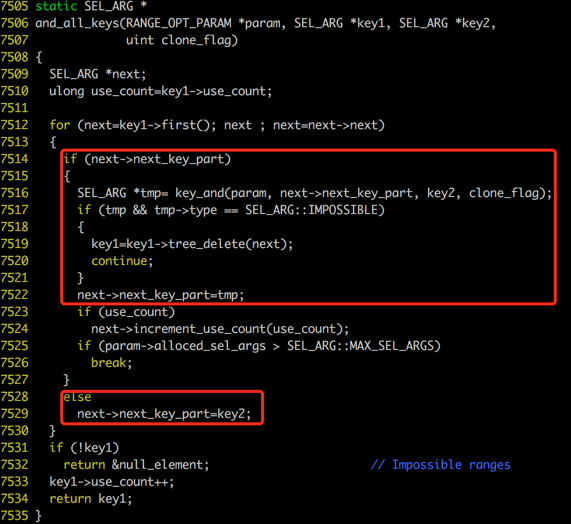
IN(1,2,3),这个SQL比上一条SQL多了一个AND条件和IN列表,因此优化器需要构造2棵红黑树,这2棵红黑树之间是如何联系起来的呢?答案就是SEL_ARG->next_key_part指针,优化器通过and_all_keys()函数将next_key_part和tree2联系起来。and_all_keys()的主要代码如下:
为了说明问题,我们还需要构造一条稍微复杂一点儿的SQL:SELECT * FROM tb
WHERE val IN(1,2,3,4,5,6,7) AND id
IN(1,2,3),这个SQL比上一条SQL多了一个AND条件和IN列表,因此优化器需要构造2棵红黑树,这2棵红黑树之间是如何联系起来的呢?答案就是SEL_ARG->next_key_part指针,优化器通过and_all_keys()函数将next_key_part和tree2联系起来。and_all_keys()的主要代码如下:
 通过代码可以看到,and_all_keys()的执行流程为:遍历key1的每一个元素,如果它的next_key_part指针非空,就将next_key_part和key2通过key_and()函数合并起来,再作为它自己的next_key_part,否则就说明它的next_key_part指针是空指针,直接将其指向key2。而key_and()函数的逻辑前文已经描述,这里不再赘述。
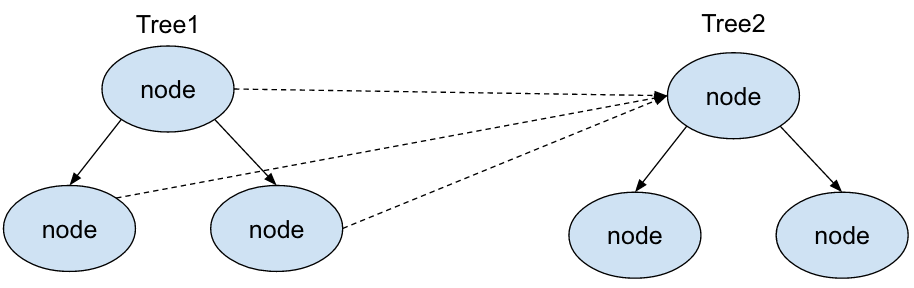
因为InnoDB二级索引本身包含了主键,也就是说索引key_val上可以索引两个字段,索引的第一个字段是val,第二个字段是id,所以在索引key_val上也就有2个key_part,第一个key_part是val,第二个key_part是id。对于SQL:SELECT
* FROM tb WHERE val IN(1,2,3,4,5,6,7) AND id IN(1,2,3),优化器通过val
IN(1,2,3,4,5,6,7)构造第一个红黑树的时候,红黑树中每个节点的next_key_part还都是空指针,然后遇到id
IN(1,2,3)构造第二棵红黑树,然后直接将第一棵红黑树的每个节点的next_key_part指针直接指向第二棵红黑树即可,示意图如下:
通过代码可以看到,and_all_keys()的执行流程为:遍历key1的每一个元素,如果它的next_key_part指针非空,就将next_key_part和key2通过key_and()函数合并起来,再作为它自己的next_key_part,否则就说明它的next_key_part指针是空指针,直接将其指向key2。而key_and()函数的逻辑前文已经描述,这里不再赘述。
因为InnoDB二级索引本身包含了主键,也就是说索引key_val上可以索引两个字段,索引的第一个字段是val,第二个字段是id,所以在索引key_val上也就有2个key_part,第一个key_part是val,第二个key_part是id。对于SQL:SELECT
* FROM tb WHERE val IN(1,2,3,4,5,6,7) AND id IN(1,2,3),优化器通过val
IN(1,2,3,4,5,6,7)构造第一个红黑树的时候,红黑树中每个节点的next_key_part还都是空指针,然后遇到id
IN(1,2,3)构造第二棵红黑树,然后直接将第一棵红黑树的每个节点的next_key_part指针直接指向第二棵红黑树即可,示意图如下:
 当分析到这里,其实已经很接近答案了,问题的关键就在于and_all_keys()函数,如果key1的next_key_part非空,那么在合并2棵树的时候,就可能耗费比较大的内存。我们再来看问题SQL:SELECT
* FROM tb WHERE val IN(1,2,3,4,5,6,7) AND id IN(1,2,3) AND id IN
(1,2,3,4),这条SQL里有3个IN列表,很明显可以使用key_val索引,优化器需要构造3棵红黑树,按照我们前面提到的算法,先将第一棵红黑树和第二棵红黑树串接起来(就像上图那样,也就是调用and_all_keys()函数),这并没有什么问题。但是第一棵树的next_key_part非空,然后再将结果和第三棵红黑树合并,那么问题来了,按照前面看到的and_all_keys算法,对于第一棵红黑树中的每一个节点,都要用next_key_part和第三棵红黑树做一次key_and(),在key_and中重复分配内存,造成内存浪费。内存结构如下:
当分析到这里,其实已经很接近答案了,问题的关键就在于and_all_keys()函数,如果key1的next_key_part非空,那么在合并2棵树的时候,就可能耗费比较大的内存。我们再来看问题SQL:SELECT
* FROM tb WHERE val IN(1,2,3,4,5,6,7) AND id IN(1,2,3) AND id IN
(1,2,3,4),这条SQL里有3个IN列表,很明显可以使用key_val索引,优化器需要构造3棵红黑树,按照我们前面提到的算法,先将第一棵红黑树和第二棵红黑树串接起来(就像上图那样,也就是调用and_all_keys()函数),这并没有什么问题。但是第一棵树的next_key_part非空,然后再将结果和第三棵红黑树合并,那么问题来了,按照前面看到的and_all_keys算法,对于第一棵红黑树中的每一个节点,都要用next_key_part和第三棵红黑树做一次key_and(),在key_and中重复分配内存,造成内存浪费。内存结构如下:
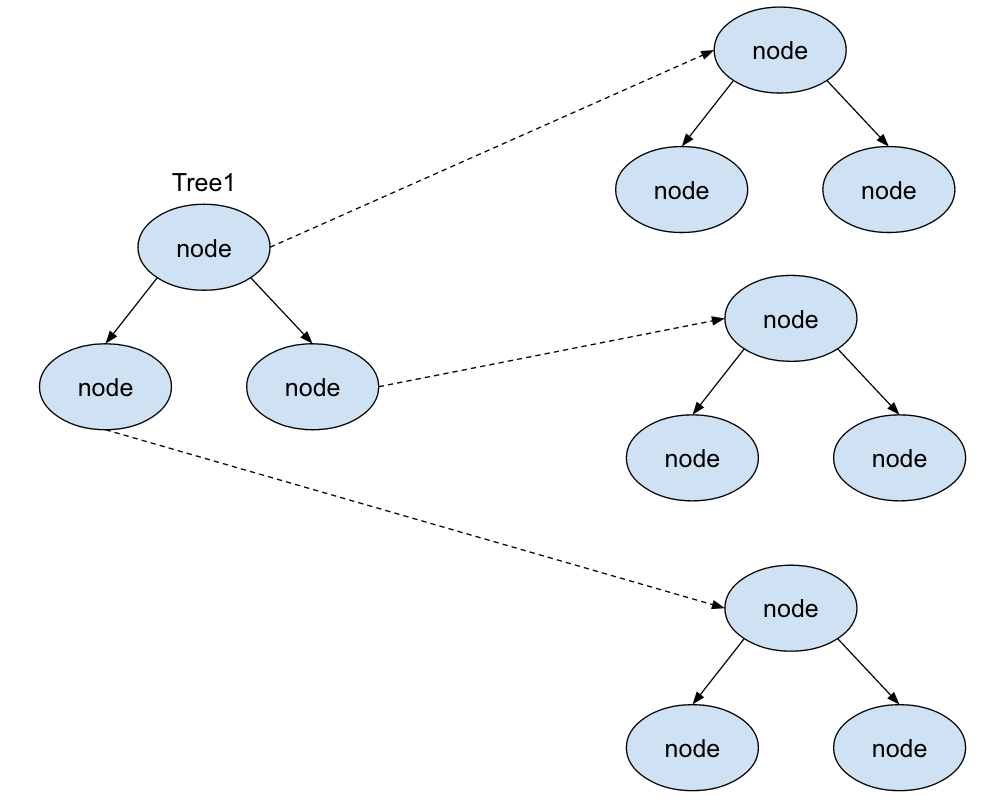 通过上图示例可以看到,第一棵红黑树的每一个节点的next_key_part都指向一个独立的红黑树,每个红黑树都是这个SQL中的两个id
IN列表的交集。在MySQL中,一个SEL_ARG占用内存为96
Bytes,考虑这篇文章最初提到的Case,val的IN列表长度为10000,两个id列表的交集长度也是10000,因此中共需要内存至少为:96
* 10000 * 10000 Bytes = 8.94 GB,符合Case中观察的的情况。
通过上图示例可以看到,第一棵红黑树的每一个节点的next_key_part都指向一个独立的红黑树,每个红黑树都是这个SQL中的两个id
IN列表的交集。在MySQL中,一个SEL_ARG占用内存为96
Bytes,考虑这篇文章最初提到的Case,val的IN列表长度为10000,两个id列表的交集长度也是10000,因此中共需要内存至少为:96
* 10000 * 10000 Bytes = 8.94 GB,符合Case中观察的的情况。
到这里为止,我们已经知道MySQL 5.6中优化器占用过多内存的原因,但是还有一个问题:为什么MySQL 5.5没有问题?
我们知道InnoDB的主键信息隐含在二级索引中,经过多次DEBUG发现,MySQL
5.5和5.6的区别是,在索引key_val上,5.6可以使用主键id,而5.5中没有使用主键id这个信息,相关代码对比如下,左边为MySQL
5.5的代码,右边为5.6的代码(sql/opt_range.cc)
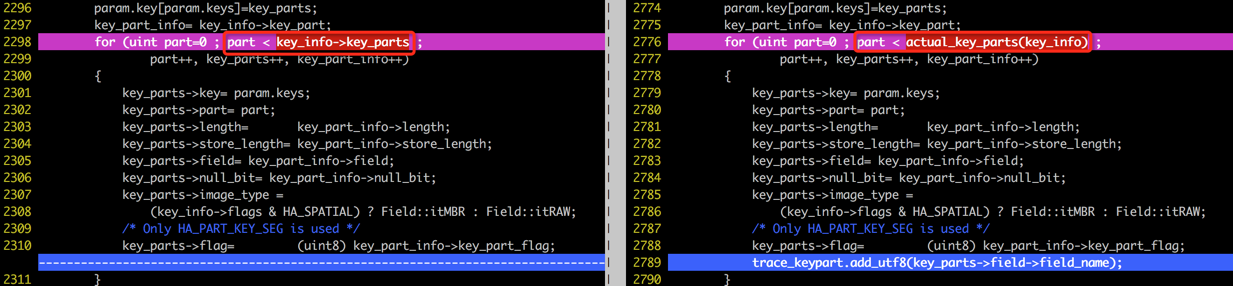 我们在表结构定义KEY
key_val
(val),在5.5中,因为索引只有一个字段,对于这个索引key_info->key_parts的值是1(索引只有一个字段val),而MySQL
5.6认为主键id也可以通过二级索引获得,所以5.6中actual_key_parts(key_info)的返回值是2(2个索引字段,第一个索引字段是val,第二个索引字段是id),也就是说MySQL
5.6中对于类型为SELECT * FROM tb WHERE val IN(…) AND id
IN(…)的查询,优化器在使用二级索引key_val的时候,需要创建2棵树并把它们通过next_key_part串接起来,而MySQL
5.5在使用二级索引key_val的时候,只能创建一棵基于val的树,所以5.5就不会遇到Case中的问题了。但是问题还没有结束,考虑这样一个问题:如果在MySQL
5.5中创建的二级索引是KEY key_val(val,
id)呢,执行Case中的SQL会占用大量的内存吗?答案是,如果创建这样的索引,5.5和5.6在这个问题上,是没什么太大的区别的,5.5也会消耗大量内存,甚至OOM。在MySQL
5.1测试也有同样的问题,在5.0未测试。
我们在表结构定义KEY
key_val
(val),在5.5中,因为索引只有一个字段,对于这个索引key_info->key_parts的值是1(索引只有一个字段val),而MySQL
5.6认为主键id也可以通过二级索引获得,所以5.6中actual_key_parts(key_info)的返回值是2(2个索引字段,第一个索引字段是val,第二个索引字段是id),也就是说MySQL
5.6中对于类型为SELECT * FROM tb WHERE val IN(…) AND id
IN(…)的查询,优化器在使用二级索引key_val的时候,需要创建2棵树并把它们通过next_key_part串接起来,而MySQL
5.5在使用二级索引key_val的时候,只能创建一棵基于val的树,所以5.5就不会遇到Case中的问题了。但是问题还没有结束,考虑这样一个问题:如果在MySQL
5.5中创建的二级索引是KEY key_val(val,
id)呢,执行Case中的SQL会占用大量的内存吗?答案是,如果创建这样的索引,5.5和5.6在这个问题上,是没什么太大的区别的,5.5也会消耗大量内存,甚至OOM。在MySQL
5.1测试也有同样的问题,在5.0未测试。
结论:无论是5.1/5.5还是5.6,只要是组合索引,在第二个索引字段上出现多个IN(…)列表,都可能造成内存消耗过大,导致OOM
### 修复方法
通过上述的分析,我们知道问题的关键是and_all_keys()函数,在合并两棵树的时候,重复分配内存。我想到的修复方法是,在合并之前,判断一下内存能否复用,如果每次合并的next_key_part都相同,则没必要进行key_and()操作,直接将next_key_part指针指过去即可。将and_all_keys()函数按如下修改后,执行Case中的SQL,内存使用不再暴涨。
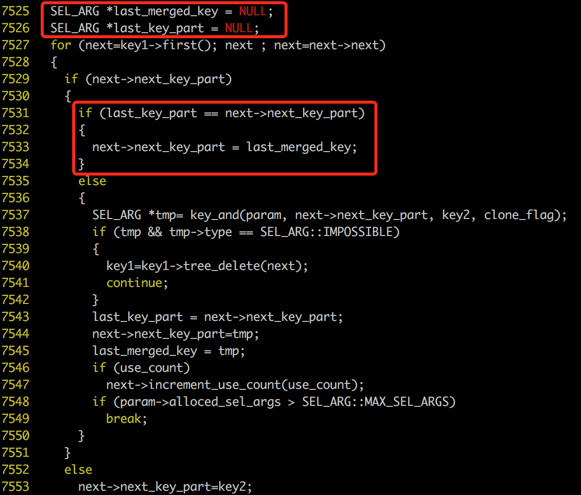
注:经过笔者测试,该 Bug 在 MySQL 5.7 中已经被修复。