MySQL 线程模型
条评论MySQL在架构上分为Server层和存储引擎层,它们的线程模型略有不同。在Server层每个连接对应一个线程,几乎没有线程并发控制,只要还可以创建连接,就会创建对应的线程,这些线程之间并发执行。而在InnoDB存储引擎层,为了防止并发线程过多,线程切换开销过大,可以限制并发线程数,从而提高性能。除此以外,MySQL Enterprise版/MariaDB/Percona还提供了在Server层控制并发的方案Thread Pool。本文将分别对他们进行介绍。
Server层线程模型
MySQL的工作模式是为每个连接分配一个线程,当客户端和MySQL服务器建立TCP连接之后,MySQL服务器就会给这个连接分配一个线程,当这个连接收到SQL时,对应的线程就执行这个SQL,而当SQL执行结束后,这个线程就去Sleep,等待客户端的新请求。这个线程会一直存活,直到客户端退出登录,并关闭连接,这个线程才会退出(或者进入MySQL的ThreadCache)。示意图如下图所示:
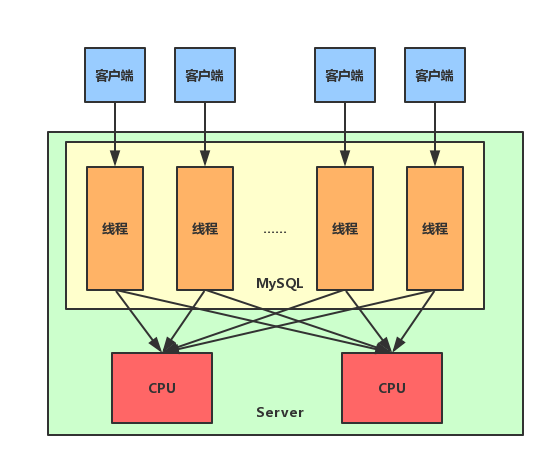 接收新连接和创建线程的如下文所示,(相关代码在sql/mysqld.cc中)
接收新连接和创建线程的如下文所示,(相关代码在sql/mysqld.cc中)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21while (!abort_loop)
{
retval= poll(fds, socket_count, -1);
for (int i= 0; i < socket_count; ++i)
{
if (fds[i].revents & POLLIN)
{
sock= pfs_fds[i]; //获取对应sock,可能是Unix套接字,或者是TCP/IP套接字
flags= fcntl(mysql_socket_getfd(sock), F_GETFL, 0);
break;
}
}
// Accept新连接
new_sock= mysql_socket_accept(key_socket_client_connection, sock,
(struct sockaddr *)(&cAddr), &length);
thd= new THD; //为连接分配内存对象,THD只是一个普通的C++ Class,是线程处理请求的参数
create_new_thread(thd); //创建新线程?
}
Thread Cache
上面这段代码好像任何学过网络编程的初学者都可以写出来,但是MySQL为了提高性能又额外添了点儿东西,叫作ThreadCache,通过set global thread_cache_size=xxx可以设置ThreadCache的大小。这个ThreadCache不同于传统意义上的线程池,ThreadCache并没有改变TCP连接和线程之间一对一的关系。我们知道操作系统创建线程是有一定开销的,ThreadCache则是为了减少创建线程的开销而设立的。
上述代码中create_new_thread(thd)的命名非常具有迷惑性,因为它并不一定真的会创建新线程,也有可能只是把thd交给别的线程,委托另外一个线程去处理这个连接请求。最终创建线程相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// create_new_thread最终会调用create_thread_to_handle_connection处理请求
void create_thread_to_handle_connection(THD *thd)
{
mysql_mutex_assert_owner(&LOCK_thread_count);
if (blocked_pthread_count > wake_pthread) //说明ThreadCache中还有空闲线程
{
/* Wake up blocked pthread */
waiting_thd_list->push_back(thd); //将thd放到队列,并通知线程拿走thd
wake_pthread++;
mysql_cond_signal(&COND_thread_cache);
}
else // 没有空闲线程了,创建新线程
{
mysql_thread_create(key_thread_one_connection,
&thd->real_id, &connection_attrib,
handle_one_connection, // 新线程入口函数为handle_one_connection
(void*) thd)
}
mysql_mutex_unlock(&LOCK_thread_count);
}
通过上面代码可以看到,如果还有空闲线程,MySQL就会把thd放到队列waiting_thd_list中,等待其他线程拿走thd,并作处理。为了了解ThreadCache的工作原理,就必须继续探究这些空闲线程是哪儿来的?为了回答这个问题,我们得从线程入口函数handle_one_connection()
开始了解,简化后相关代码如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// handle_one_connection最终会调用do_handle_one_connection处理请求
void do_handle_one_connection(THD *thd)
{
for (;;)
{
// 通过循环处理这个连接上的请求,直到连接被关闭
while (thd_is_connection_alive(thd)) //连接没有关闭
{
if (do_command(thd)) //在网络上等待,接收并处理一条SQL
break;
}
// 当上一个连接的请求全都被处理完时,在条件变量COND_thread_cache上等待
if (blocked_pthread_count < max_blocked_pthreads &&
!abort_loop && !kill_blocked_pthreads_flag)
{
// Block pthread
while (!abort_loop && !wake_pthread && !kill_blocked_pthreads_flag)
mysql_cond_wait(&COND_thread_cache, &LOCK_thread_count);
thd= waiting_thd_list->front(); // 从队列中取出第一个元素
waiting_thd_list->pop_front();
}
}
}
以上就是ThreadCache的逻辑,通过代码可以看到并不存在一个像内存之类的Cache把线程都缓存起来,等需要时再把线程从Cache中取出。MySQL需要的是一个条件变量COND_pthread_cache,和一个队列waiting_thd_list。当服务完一个连接之后,空闲的线程并不会退出,而是在条件变量上等待,而waiting_thd_list队列里放的是线程所需要的参数。当新的TCP连接建立时,主线程会先尝试把thd放到队列里,如果可以的话,然后主线程只需要在条件变量上signal一次即可,然后空闲的线程就会从队列中把thd拿走,并为这个连接服务。只有没有空闲线程时,MySQL才需要创建新线程。
InnoDB 线程模型
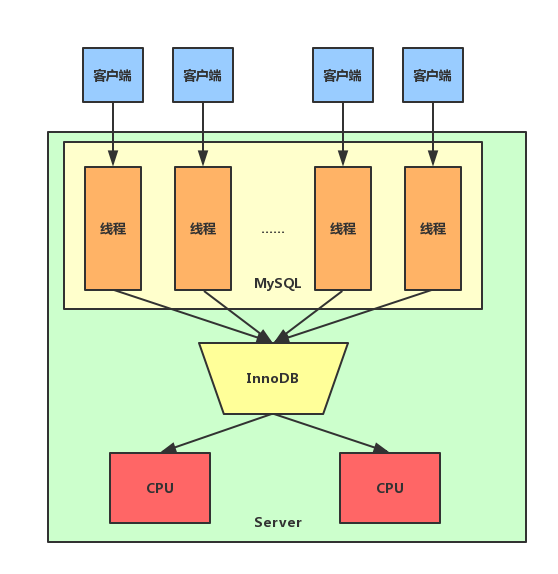
通过前面的叙述可以我们知道,MySQL在Server层根本就没有对并发线程的数量进行控制,当MySQL的并发连接数增加时,就会导致对应的线程数量增加。这样可能把机器的大量CPU资源都耗费在线程切换上了,导致性能急剧下降。InnoDB为了缓解这种情况,通过设置系统变量set
global innodb_thread_concurrency =
x可以控制内部并发线程的数量,也就是最多允许innodb_thread_concurrency个线程同时在InnoDB内部运行。也就是说在Server层可以创建很多线程,但是到了InnoDB内部,只会有少量线程并发执行,其他线程都处于sleep状态。示意图如下:
 这种模型在InnoDB里是怎么实现的呢?熟悉MySQL代码的同学应该都知道,InnoDB通过ha_innobase::write_row(),
ha_innobase::update_row(), ha_innobase::delete_row(),
ha_innobase::index_read(),
ha_innobase::general_fetch()等接口操作数据,一个接口只操作一行数据。InnoDB在这些接口中进行并发控制。拿write_row()举例来说,相应代码如下:
这种模型在InnoDB里是怎么实现的呢?熟悉MySQL代码的同学应该都知道,InnoDB通过ha_innobase::write_row(),
ha_innobase::update_row(), ha_innobase::delete_row(),
ha_innobase::index_read(),
ha_innobase::general_fetch()等接口操作数据,一个接口只操作一行数据。InnoDB在这些接口中进行并发控制。拿write_row()举例来说,相应代码如下:
1
2
3
4
5
6
7int ha_innobase::write_row(uchar* record) {
innobase_srv_conc_enter_innodb(prebuilt->trx); // 操作数据前,先控制并发
error = row_insert_for_mysql((byte*) record, prebuilt); // 操作数据
innobase_srv_conc_exit_innodb(prebuilt->trx);
}
InnoDB通过调用函数innobase_srv_conc_enter_innodb()来控制并发,只有当InnoDB内部并发数小于限制值,才允许进行后续操作,否则就等待。我们知道一个存储引擎API只能操作一行数据,那么如果一条SQL修改很多条纪录呢,那就需要调用很多次InnoDB的API,如果对每行数据操作都要进行并发控制,那么对性能还是有一定影响的。InnoDB想了一个办法是,一旦线程进入InnoDB内核,就给他n个tickets,意思是它后续可以进行n次操作,不需要重新申请进入InnoDB内核,当这n个tickets用完之后,如果它还想进入InnoDB内核,那么对不起,请重新获取tickets(当然还是n个tickets)。每次获取tickets的数量对应的InnoDB变量是innodb_concurrency_tickets,可以动态调整。在MySQL
5.5以及之前,innodb_concurrency_tickets的默认值是500,从5.6开始默认值是5000。相应代码如下:
1
2
3
4
5
6
7
8
9
10void innobase_srv_conc_enter_innodb(trx_t * trx) {
if (srv_thread_concurrency) {
if (trx->n_tickets_to_enter_innodb > 0) { // 线程已有tickets
--trx->n_tickets_to_enter_innodb;
} else { // 线程没有tickets
srv_conc_enter_innodb(trx); // 申请tickets
}
}
}
通过上述代码很明显可以看到,一旦线程拿到了tickets,并发控制时就只是消耗一个tickets而已,其它的什么也不用干,代价非常低。如果没有tickets或者tickets已经用完了,就需要申请tickets了。申请tickets时,InnoDB支持两种方式,一种方式时当gcc不支持原子操作时,InnoDB使用mutex和cond实现tickets的申请;另外一种方式是当gcc支持原子操作时,InnoDB使用无锁方式申请tickets。现代机器体系结构以及gcc都支持了原子操作,所以一般使用无锁方式比较多。但是这里有一个问题:申请InnoDB的tickets是做并发控制用的,如果并发数超出限制了,InnoDB就不能分配tickets,而是要让当前线程等待,既然是使用无锁方式分配tickets,那么线程怎么等呢?答案在以下代码中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// srv_conc_enter_innodb 会调用此函数申请tickets
void srv_conc_enter_innodb_with_atomics(trx_t * trx) { // 无锁方式申请tickets
for (;;) {
// srv_conc.n_active是当前已经进入InnoDB内核的线程数,srv_thread_concurrency是并发上限
if (srv_conc.n_active < (lint) srv_thread_concurrency) {
n_active = os_atomic_increment_lint(&srv_conc.n_active, 1);
if (n_active <= srv_thread_concurrency) { // 如果并发没有超
srv_enter_innodb_with_tickets(trx); // 分配tickets
return;
}
(void) os_atomic_decrement_lint(&srv_conc.n_active, 1);
}
os_thread_sleep(srv_thread_sleep_delay); // 通过sleep释放CPU资源
}
}
除此以外,还有一个问题需要考虑:我们知道InnoDB使用行锁进行事务并发控制,如果一个进入InnoDB的事务需要等另外一个事务释放锁,这个时候该怎么办,要让当前线程退出InnoDB内核吗?是需要的,因为如果不退出可能产生死锁:为了简单起见,我们假设innodb_thread_concurrency的值是1,trx1进入InnoDB内核,trx2由于由于InnoDB并发数量的限制拿不到tickets,就无法往下执行。然后trx1修改数据,如果很不幸需要等trx2释放锁,那么trx1和trx2就会相互等待。所以在事务需要等锁时,必须先从InnoDB内核中出来再等锁,当拿到锁之后,再重新进入InnoDB内核。这一方面可以提高并发性,另一方面避免了死锁。InnoDB事务在等锁时,会调用函数lock_wait_suspend_thread(),其内部实现如下:
1 | void lock_wait_suspend_thread(que_thr_t* thr) { |
通过上面的总结,我们可以看到InnoDB对线程并发的控制粒度是非常细的,所有进入InnoDB内核的线程都是在进行CPU操作,当需要等锁时,线程会退出InnoDB内核,允许其他线程进入InnoDB,InnoDB的并发数控制策略可以保持CPU总是处于工作状态。但是在Server层,如果连接数很高(连接数超过2千),仍然会占用大量的线程,线程切换开销不可忽视,造成性能下降。为了解决这个问题,还需要更加彻底的方案。
Thread Pool
Thread
Pool在MySQL官方是以Enterprise版plugin的形式出现的,而在MariaDB和Percona都是侵入MySQL源码的,它们在实现上大同小异,并没有本质区别。这里主要分析Percona的Thread
Pool实现。如前文所述,MySQL
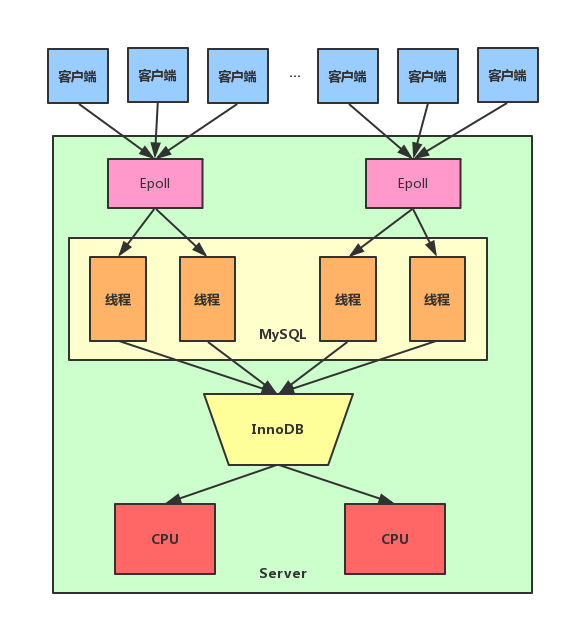
Server在每当有一个客户端连接进来时,都会创建一个线程来服务这个连接。而Thread
Pool的思想是将连接和线程解绑,连接和线程之间不再是一对一的关系,而是m对n的关系。具体做法是通过epoll监听网络端口,一旦有客户端数据需要处理,就把这个连接放入队列,让后台线程池从队列中取出连接信息,并服务这个连接。也就是说MySQL的连接数可以非常高,但是线程数量可以只有几十个。通过Thread
Pool彻底解决线程数量过多,导致性能下降的问题,示意图如下:
 下面将通过源码来分析Percona
线程池的实现(Percona的线程池同时支持Linux和Windows,本文只分析Linux下的实现)。MySQL为服务连接预留了接口,定义如下:
下面将通过源码来分析Percona
线程池的实现(Percona的线程池同时支持Linux和Windows,本文只分析Linux下的实现)。MySQL为服务连接预留了接口,定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14// file: sql/scheduler.h
/* Functions used when manipulating threads */
struct scheduler_functions
{
uint max_threads;
bool (*init)(void);
bool (*init_new_connection_thread)(void);
void (*add_connection)(THD *thd); // 当新连接到来时,会回调此函数
void (*thd_wait_begin)(THD *thd, int wait_type);
void (*thd_wait_end)(THD *thd);
void (*post_kill_notification)(THD *thd);
bool (*end_thread)(THD *thd, bool cache_thread);
void (*end)(void);
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// file: sql/mysqld.cc
if (thread_handling <= SCHEDULER_ONE_THREAD_PER_CONNECTION) // 默认配置
one_thread_per_connection_scheduler(thread_scheduler, &max_connections,
&connection_count);
else if (thread_handling == SCHEDULER_NO_THREADS)
one_thread_scheduler(thread_scheduler);
else // 配置为线程池
pool_of_threads_scheduler(thread_scheduler, &max_connections,
&connection_count);
// file: sql/thread_common.cc
// 线程池的回调实现
static scheduler_functions tp_scheduler_functions=
{
0, // max_threads
NULL,
NULL,
tp_init, // init
NULL, // init_new_connection_thread
tp_add_connection, // add_connection
tp_wait_begin, // thd_wait_begin
tp_wait_end, // thd_wait_end
tp_post_kill_notification, // post_kill_notification
NULL, // end_thread
tp_end // end
};
void pool_of_threads_scheduler(struct scheduler_functions *func,
ulong *arg_max_connections,
uint *arg_connection_count)
{
*func = tp_scheduler_functions; // 将接口初始化为线程池实现
func->max_threads= threadpool_max_threads;
func->max_connections= arg_max_connections;
func->connection_count= arg_connection_count;
scheduler_init();
}
当新连接到来时,mysql会掉用tp_add_connection()函数来处理该请求,其源码实现并没有什么magic,内部使用了2个队列,一个优先级高,另一个优先级低。当epoll认为有数据到来时,会把连接放入队列中,后台线程从队列中取出连接,服务该请求。
这里有2个问题需要注意,一个是Percona实现的线程池是非常粗粒度的,当客户端发送SQL到MySQL Server时,如果是在内部等锁,并不会释放CPU执行权,只有等网络才会释放CPU执行权。也就是说SQL在InnoDB内部等锁,仍然会占用线程池的一个线程,可能导致其他请求不能执行。另外Dump线程在等待binlog更新时,也会占用线程池的一个线程,如果从库数量过多,对线程池的性能会产生一定影响。
另一个问题是如果线程池全部忙碌,会阻止新连接的建立,表现出来的现象是无法登录mysql server(即使是dba也无法登录)。Percona采用的方案是用一个额外的端口来解决这个问题,通过extra_port来配置端口,通过此端口进来的连接,仍然是每个连接对应一个线程。